小数据之XX招聘网自动翻页采集
小数据之XX招聘网自动翻页采集
1.技术路线
- python 3.6.0
- scrapy 1.4.0
2.任务
爬取腾讯招聘网站的自动翻页的数据采集
3.分析
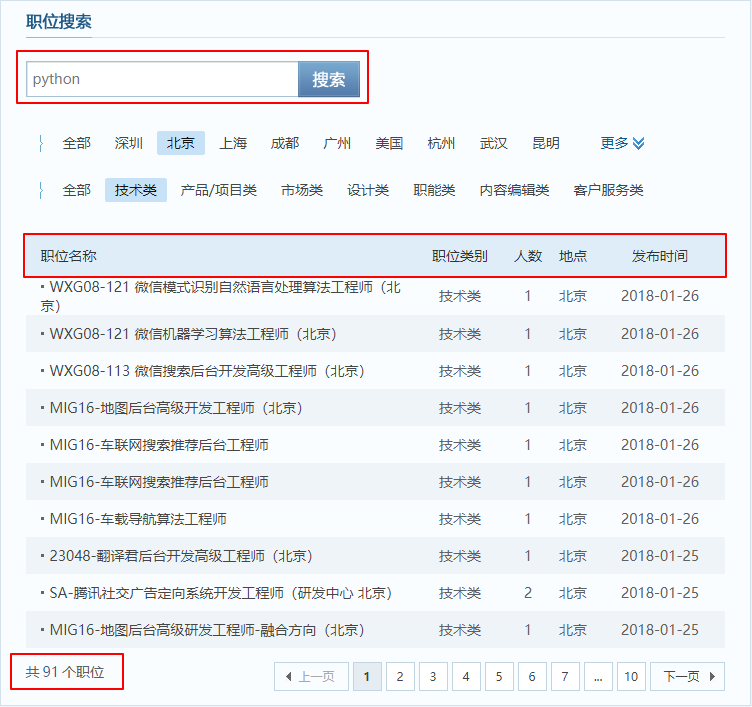
image.png
注意
- URL组成
- https://hr.tencent.com/position.php?lid=2156&tid=87&keywords=自然语言处理start=0
- 其中:
- lid=2156 代表地点在北京
- tid=87 代表方向为技术类
- keywords 代表搜索职位
- start 代表当前页面第一条数据的序号
- 爬取目标
- 1.职位名称
- 2.职位类别
- 3.职位人数
- 4.职位地点
- 5.发布时间
- 6.职位详情
4.运行结果

image.png
5.源码
- GitHub
- 欢迎Fork,一起讨论学习
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan
作者:Jasonhaven.D
链接:http://www.jianshu.com/u/ed031e432b82
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




